728x90
반응형
반응형

Tidy Data란?
- 데이터를 **관측값(row)**과 **특성값(column)**으로 정리하는 것.
- *각 행(row)**은 하나의 관측값에 해당하고, **각 열(column)**은 하나의 변수(특성)를 의미.


먼저 Pandas로 데이터를 불러오고 구조를 확인합니다.
import pandas as pd
# CSV 파일 불러오기
df = pd.read_csv('../data/example.csv')
# 데이터 구조 확인
print(df.head())
print(df.info())
Tidy Data로 변환하기
1. Pivot을 활용한 데이터 정리
- 이 배열은 다양한 데이터 분석, 시각화, 수학적 연산 등에 활용될 수 있습니다.
x = np.arange(0,9+1)
y = x
plt.plot( x, y )
# 설명필요없고 표만 보여줘라 plt.show()
plt.show()
코드분석
- np.arange() : NumPy의 arange 함수를 사용합니다.
- 첫 번째 인자 0: 시작값을 나타냅니다.
- 두 번째 인자 9+1: 끝값을 나타냅니다. arange 함수는 끝값을 포함하지 않으므로, 9를 포함하기 위해 9+1을 사용합니다.
- plt.show() : 함수로 그래프를 화면에 출력합니다.
출력

2. Bar Charts(countplot)
2-1. countplot을 활용한 데이터 정리
- 이 코드는 Seaborn 라이브러리를 사용하여 카테고리별 개수를 나타내는 막대 그래프(countplot)를 생성합니다
import seaborn as sb
base_color = 'orange'
base_order = df['generation_id'].value_counts().index
base_order = base_order[ : : -1]
sb.countplot(data=df, x='generation_id', color=base_color,order=base_order )
plt.show()
코드분석
- base_order = base_order[ : :-1] :
- 슬라이싱을 통해 **base_order**를 역순으로 뒤집습니다. 즉, 빈도가 가장 적은 값부터 많은 값 순으로 정렬됩니다.
- order=base_order : x축에 나타날 카테고리 순서를 base_order로 지정합니다 (빈도가 낮은 순서부터 높은 순서)

출력

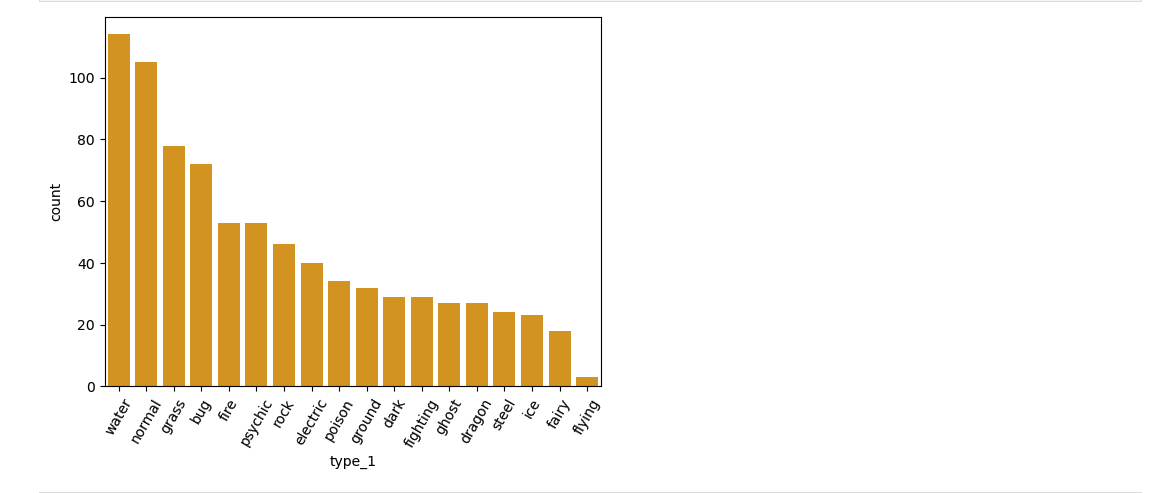
2-1. countplot 의 형태 변환
sb.countplot(data=df, x='type_1', color=base_color, order = base_order)
# 글자 방향 돌리는것 plt.xticks(rotation = 60)
plt.xticks(rotation = 60)
plt.show()
코드분석
- plt.xticks(rotation = ) : 글자 방향 돌리는것 (60도 만큼 돌려라! => plt.xticks(rotation = 60))
출력
3. Pie Charts
- 일반적으로 몇 개의 범주를 나타내는 데 사용됩니다.
- 데이터의 전체에 대한 각 부분의 비율을 원형으로 표현하는 그래프입니다.
- 간단하고 비전문가도 이해하기 쉽습니다.
# wedgeprops = {'width':0.7} => 가운데 구멍 뚫어 주는거
# startangle = 90) => 방향 돌려주는거 90도로 방향 전환
plt.pie(data, labels = data.index, wedgeprops = {'width':0.7} , startangle = 90)
plt.title('Gennernation Id Pie Chart')
# 차트 설명 오른쪽 아래로 내려라 (loc = 'lower right')
plt.legend(loc = 'lower right')
plt.show()
코드분석
- wedgeprops = {'width': } : 가운데 구멍 뚫어 주는거
- startangle = : 방향 돌려주는거 ( 예 : 90도로 방향 전환 = > startangle = 90)
- loc = 'lower right' : 차트 설명 오른쪽 아래로 내려라
출력

4. histogram
- 히스토그램은 데이터를 특정 구간(bin)으로 나눌수 있습니다.
- 각 구간에 속하는 데이터의 개수를 시각적으로 나타내는 그래프입니다.
- 데이터의 분포를 이해하거나 특정 패턴을 파악하는 데 유용합니다.




4-1. data histogram
# 구간을 설정
df['speed'].min()
df['speed'].min()
# 구간만드는 방법
np.arange( 5, 160+7, 5 )
np.arange( df['speed'].min(),df['speed'].min()+7, 5 )my_bins = np.arange( df['speed'].min(),df['speed'].min()+7, 5 )
plt.hist(data = df, x = 'speed', rwidth = 0.8, bins = 10)
plt.title('speed hist. bins 20')
plt.xlabel('speed')
plt.ylabel('count')
plt.show()
코드분석
- my_bins = np.arange( df['speed'].min(),df['speed'].min()+, )
- 히스토그램에서 구간(bin)의 경계값을 수동으로 지정하기 위함
- plt.xlabel('speed') : x축 레이블을 'speed'로 설정
- plt.ylabel('count') : y축 레이블을 'count'로 설정
출력

4-1. Figures, Axes, Subplots 활용

plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.hist(data = df, x = 'speed', rwidth = 0.9, bins = 10)
plt.title('speed hist. bins 10')
plt.xlabel('speed')
plt.ylabel('count')
plt.subplot(1, 2, 2)
plt.hist(data = df, x = 'speed', rwidth = 0.9, bins = 20)
plt.title('speed hist. bins 20')
plt.xlabel('speed')
plt.ylabel('count')
plt.show()
코드분석
- plt.figure(figsize=( , )) : 크기 조정 [ 가로 : 세로 ]위와같이 사용하면 전체 크기조정가능 각 플롯에 사용하면 각 플롯에 적용
출력

728x90
반응형
'Python > 이론' 카테고리의 다른 글
| 115. [Python] [Pandas] 프로그래밍 기본 사항 : DataBivariate (여러개의 변수간의) Visualization 방법 (0) | 2025.01.23 |
|---|---|
| 112. [Python] [Pandas] 프로그래밍 기본 사항 : CONCATENATING AND MERGING (0) | 2025.01.23 |
| 111. [Python] [Pandas] 프로그래밍 기본 사항 : Pandas Series의 문자열 메서드 (str.) (0) | 2025.01.23 |
| 110. [Python] [Pandas] 프로그래밍 기본 사항 : Dealing with NaN (0) | 2025.01.22 |
| 109. [Python] [Pandas] 프로그래밍 기본 사항 : Dataframe (0) | 2025.01.22 |


