728x90
반응형

Dealing with NaN 이론

1. NaN 값 탐지하기
데이터프레임에 NaN 값을 확인하려면 다음 메서드를 사용할 수 있습니다:
- isna() 또는 isnull(): 데이터프레임에서 NaN 여부를 Boolean 값으로 반환합니다.
- notna() 또는 notnull(): NaN이 아닌 값을 Boolean 값으로 반환합니다.
예제:
# DataFrame 생성
items2 = [
{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes': 8, 'suits': 45},
{'bikes': 15, 'glasses': 50, 'pants': 5, 'shirts': 2, 'shoes': 5, 'suits': 7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes': 10}
]
df = pd.DataFrame(items2, index=['store 1', 'store 2', 'store 3'])
# NaN 탐지
df.isna()
출력
: bikes pants watches glasses shirts shoes suits
| store 1 | False | False | False | True | False | False | False |
| store 2 | False | False | False | False | False | False | False |
| store 3 | False | False | False | False | True | False | True |


2. NaN 값 카운트하기
2-1. 열별 NaN 값 수
df.isna().sum()
출력
bikes 0
pants 0
watches 0
glasses 1
shirts 1
shoes 0
suits 1
dtype: int64

2-1. 전체 데이터프레임 NaN 값 수
py
df.isna().sum().sum()
출력
: 3
3. NaN 처리하기
데이터에서 NaN을 처리하는 일반적인 방법은 다음 두 가지입니다.
3-1. NaN 값 제거하기
- dropna(): NaN이 포함된 행 또는 열을 삭제합니다.
df.dropna()
출력
: bikes pants watches glasses shirts shoes suits
| store 2 | 15 | 5 | 10 | 50 | 2 | 5 | 7 |

3-2. NaN 값을 채우기
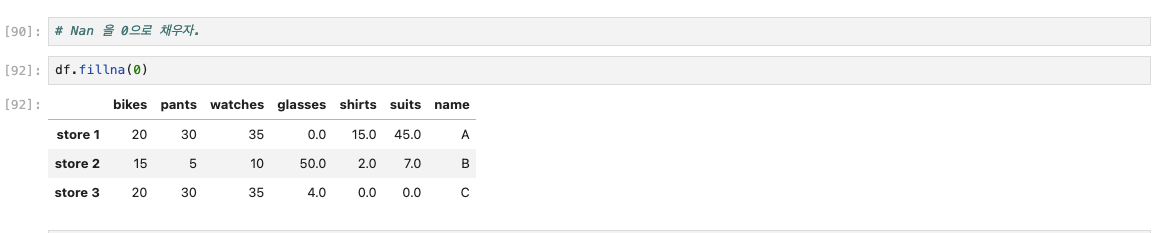
- fillna(): NaN을 특정 값으로 대체합니다.
# 모든 NaN을 0으로 채우기
df.fillna(0)
출력
: bikes pants watches glasses shirts shoes suits
| store 1 | 20 | 30 | 35 | 0 | 15 | 8 | 45 |
| store 2 | 15 | 5 | 10 | 50 | 2 | 5 | 7 |
| store 3 | 20 | 30 | 35 | 4 | 0 | 10 | 0 |
3-3. NaN 값을 대체하기
- 또는 평균값으로 채울 수 있습니다:
df.fillna(df.mean())


Dealing with NaN 실습
4. NaN 처리 실습
문제
책 제목과 저자, 그리고 사용자별 별점 데이터가 있습니다. 이 데이터에서 NaN 값을 평균값으로 대체하세요.
# 데이터 생성
books = pd.Series(['Great Expectations', 'Of Mice and Men', 'Romeo and Juliet', 'The Time Machine', 'Alice in Wonderland'])
authors = pd.Series(['Charles Dickens', 'John Steinbeck', 'William Shakespeare', 'H. G. Wells', 'Lewis Carroll'])
user_1 = pd.Series([3.2, np.nan, 2.5])
user_2 = pd.Series([5, 1.3, 4.0, 3.8])
user_3 = pd.Series([2.0, 2.3, np.nan, 4])
user_4 = pd.Series([4, 3.5, 4, 5, 4.2])
# 데이터프레임 생성
my_data = {'Book Title': books, 'Author': authors, 'User1': user_1, 'User2': user_2, 'User3': user_3, 'User4': user_4}
df = pd.DataFrame(my_data)
풀이
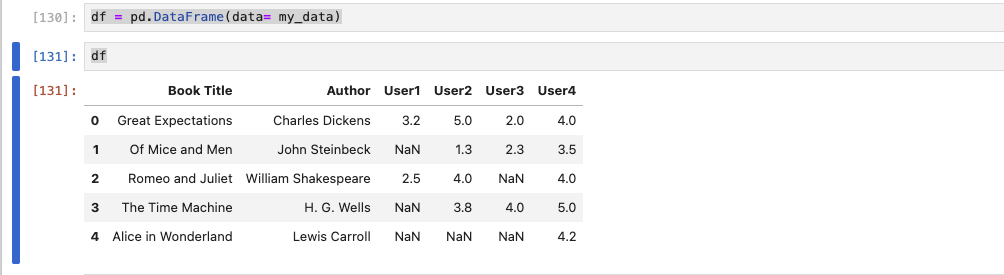
# 1. 딕셔너리를 만들고,
my_data = { 'Book Title' : books, 'Author' : authors , 'User1':user_1, 'User2':user_2, 'User3': user_3, 'User4': user_4 }
df = pd.DataFrame(data= my_data)
출력
df
# 2. 데이터프레임으로 만든 후,
df.mean(numeric_only=True)
# 3. nan을 평균값으로 채운다.
# 평균값 계산
df.fillna(df.mean(numeric_only=True), inplace=True)
출력
: Book Title Author User1 User2 User3 User4
| Great Expectations | Charles Dickens | 3.20 | 5.00 | 2.00 | 4.00 |
| Of Mice and Men | John Steinbeck | 2.85 | 1.30 | 2.30 | 3.50 |
| Romeo and Juliet | William Shakespeare | 2.50 | 4.00 | 2.77 | 4.00 |
| The Time Machine | H. G. Wells | 2.85 | 3.80 | 4.00 | 5.00 |
| Alice in Wonderland | Lewis Carroll | 2.85 | 3.53 | 2.77 | 4.20 |
728x90
반응형
'Python > 이론' 카테고리의 다른 글
| 112. [Python] [Pandas] 프로그래밍 기본 사항 : CONCATENATING AND MERGING (0) | 2025.01.23 |
|---|---|
| 111. [Python] [Pandas] 프로그래밍 기본 사항 : Pandas Series의 문자열 메서드 (str.) (0) | 2025.01.23 |
| 109. [Python] [Pandas] 프로그래밍 기본 사항 : Dataframe (0) | 2025.01.22 |
| 108. [Python] [Pandas] 프로그래밍 기본 사항 : Series (0) | 2025.01.22 |
| 107. [Python] [Pandas] 프로그래밍 기본 사항 : Series Attributes (0) | 2025.01.21 |


