AI/이론
128. [Python] [Machine Learning] : Logistic Regression(분류)
천재단미
2025. 1. 28. 15:10
728x90
반응형

반응형
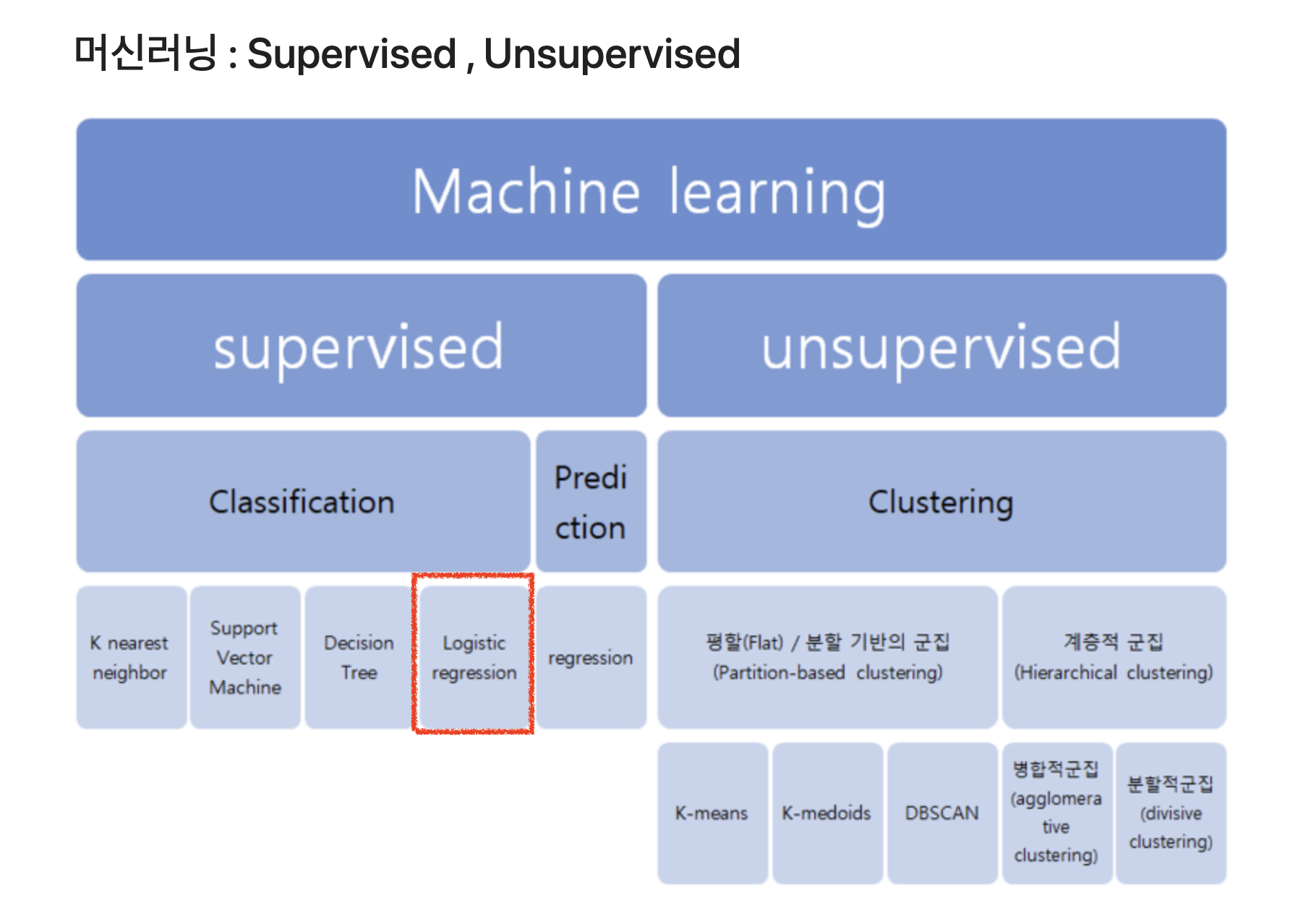
로지스틱 회귀(Logistic Regression)는 머신러닝에서 분류(Classification) 문제를 해결하기 위한 기본적인 알고리즘입니다.

1. 로지스틱 회귀(Logistic Regression)란?
로지스틱 회귀는 데이터를 0과 1로 분류하는 이진 분류(Binary Classification) 알고리즘입니다. 선형 회귀와 유사하지만, 예측 값이 확률(0~1 사이 값)을 출력하도록 설계되었습니다.
1-1. 주요 특징
- 입력 데이터에 선형 함수(가중치와 편향)를 적용.
- 출력 값은 시그모이드 함수(Sigmoid Function)를 통해 확률로 변환.
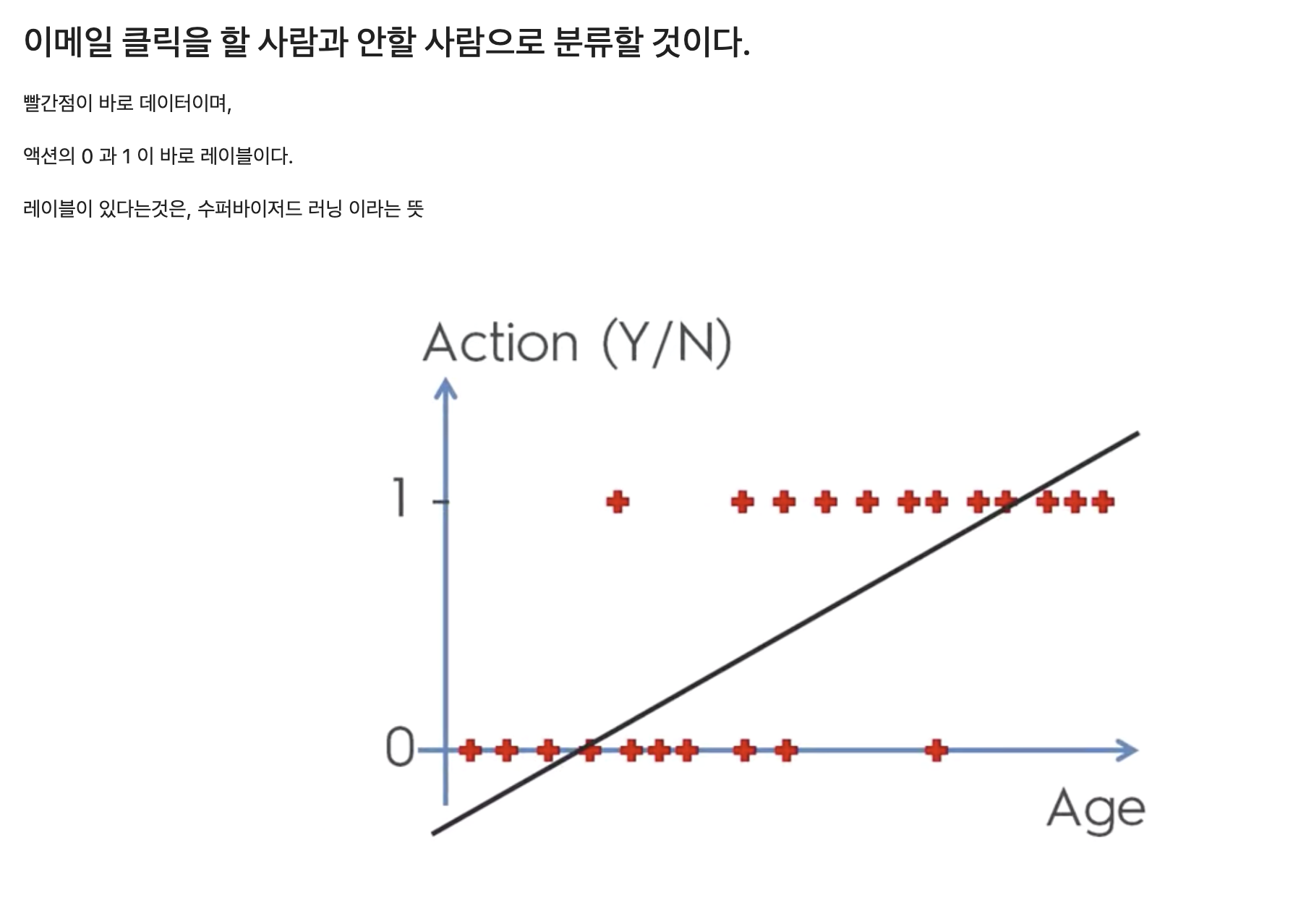
- 예: 이메일이 스팸인지 아닌지(1/0), 종양이 악성인지 양성인지(1/0).

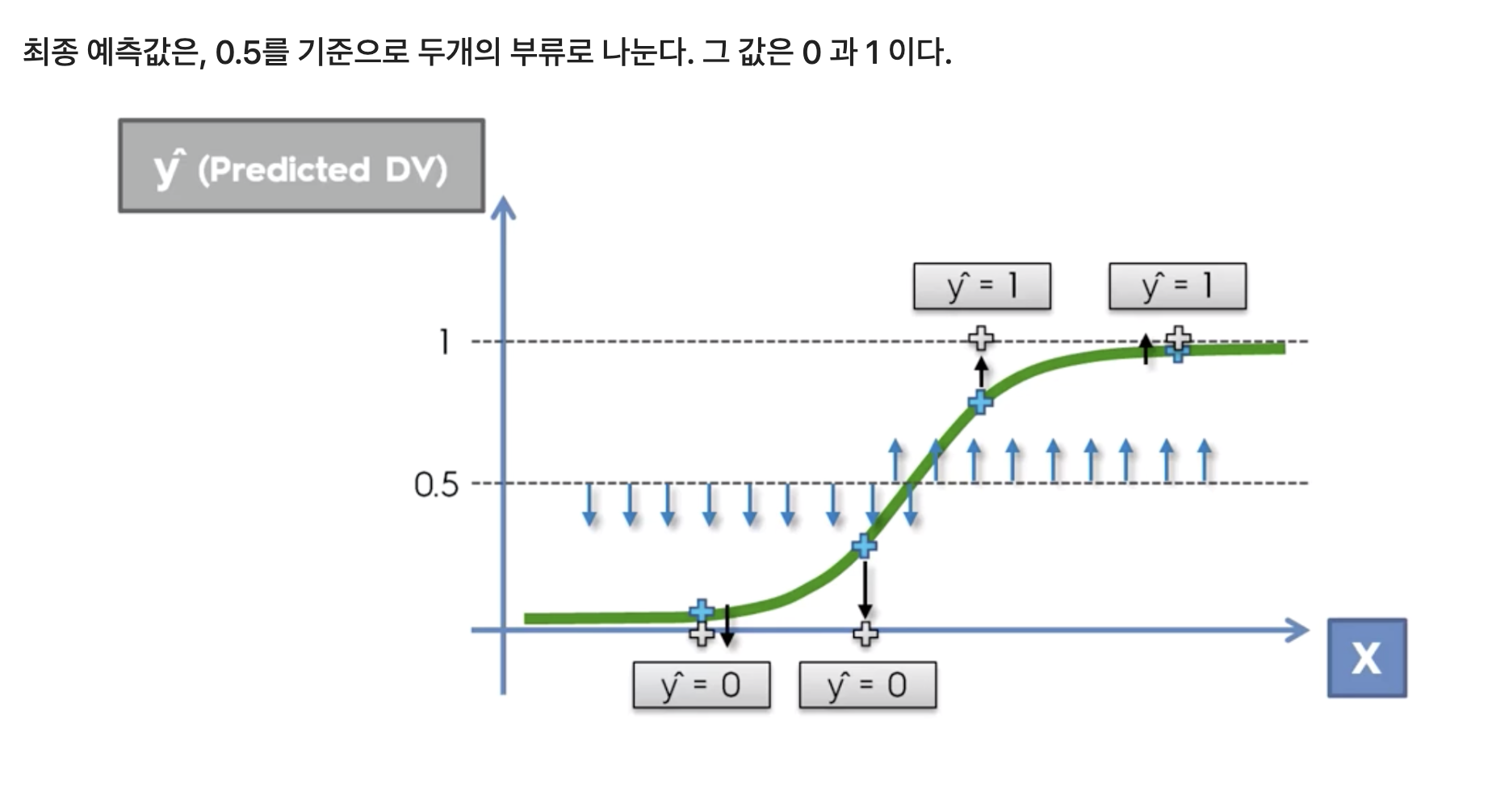
1-2. 시그모이드 함수
σ(z)=1/(1+e(−z))σ(z) = 1 / (1 + e^(-z))
σ(z)=1/(1+e(−z))
- z: 선형 회귀 결과
- 출력: 0과 1 사이의 값




분류의 문제
# 나이와 연봉으로 분석해서, 물건을 구매할지 안할지를 분류하자!!
2. 데이터 준비 및 탐색
2-1. 데이터 로드
첨부된 데이터를 읽어옵니다.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('../data/Social_Network_Ads.csv')
df.head(2)
2-2. 데이터 컬럼 설명
데이터는 다음과 같은 컬럼을 포함합니다:
- Feature 컬럼: 입력 데이터 (예: 나이, 소득 등)
- Target 컬럼: 출력 데이터 (0 또는 1)

2-3. 데이터 전처리
결측값 처리 및 필요시 정규화(Normalization)를 진행합니다.
# 결측치 확인
df.isna().sum()
# X, y 구분
y = df['Purchased']
X = df[['Age','EstimatedSalary']]
3. 모델 훈련 및 테스트
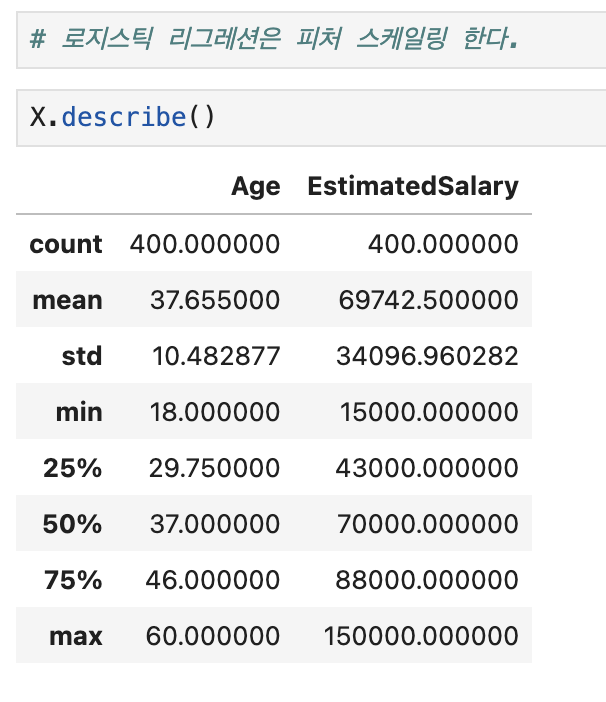
3-1. 데이터 분할
from sklearn.model_selection import train_test_split
scaler_X = StandardScaler()
X = scaler_X.fit_transform( X )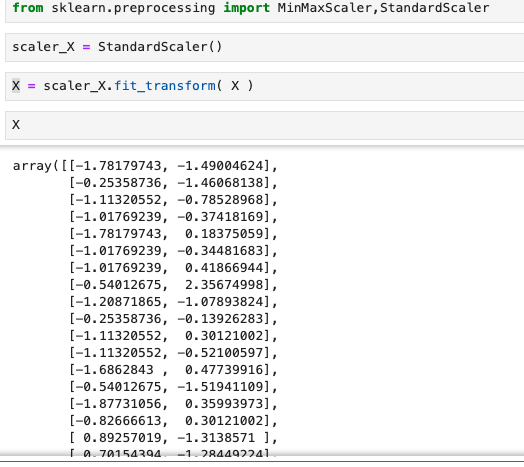
# train / test 준비
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size = 0.2, random_state = 27)
3-2. 로지스틱 회귀 모델 생성
from sklearn.linear_model import LogisticRegression
# 모델 생성
classifier = LogisticRegression()
# 모델 훈련
classifier.fit(X_train, y_train)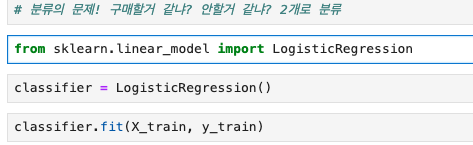

3-3. 예측
y_pred = model.predict(X_test)

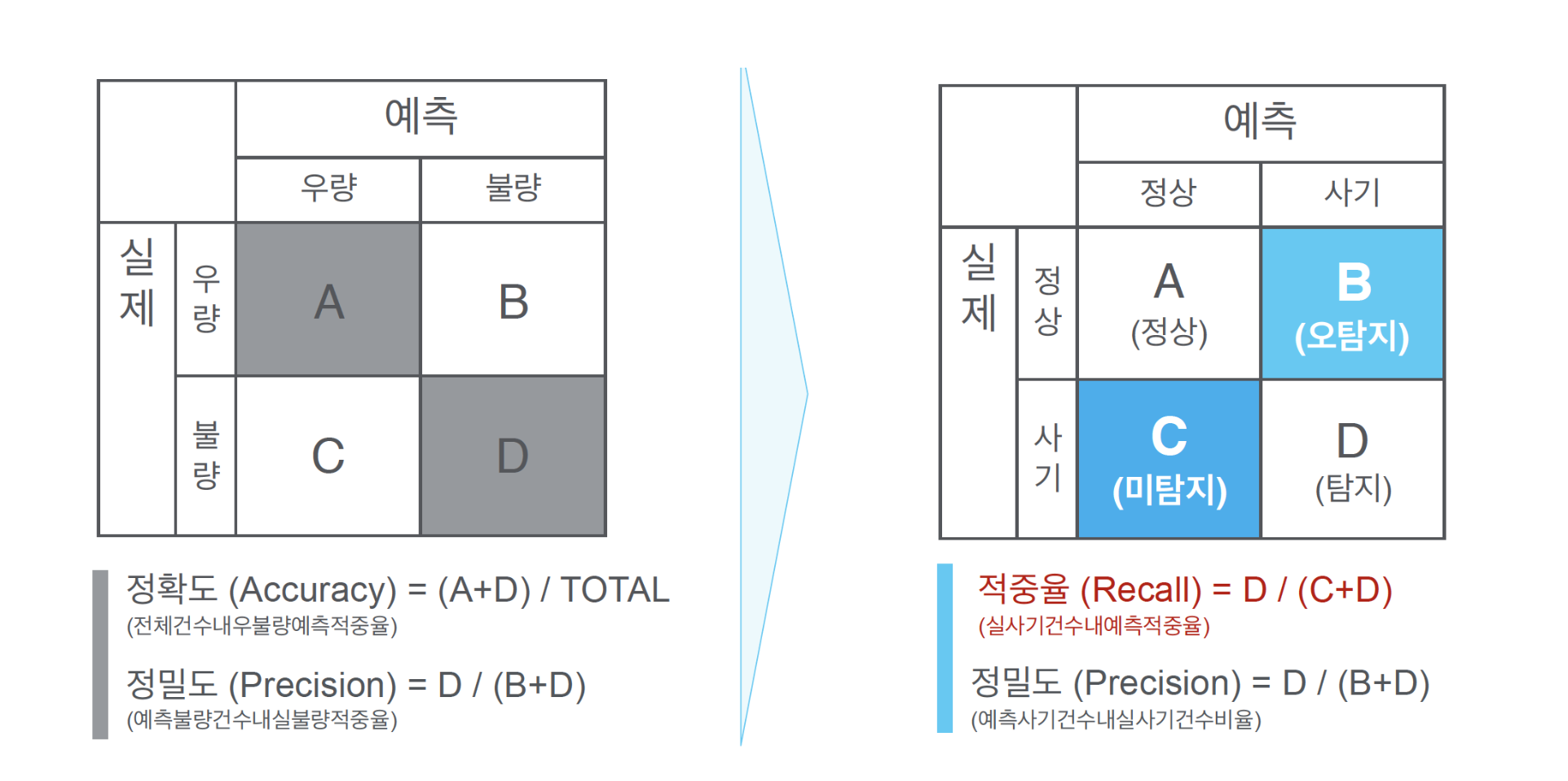
4. 모델 평가


from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
cm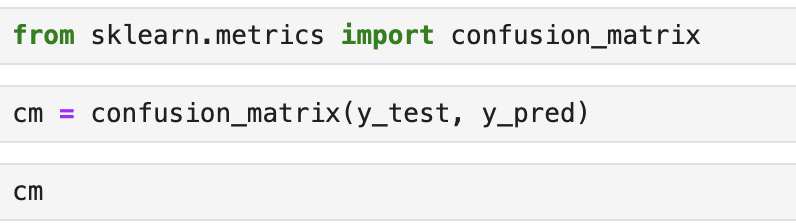
출력
array([[49, 5],
[ 7, 19]])
# 정확도 accuracy
(49 + 19) / cm.sum()
# 0.85
4-1. 정확도(Accuracy) 평가
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)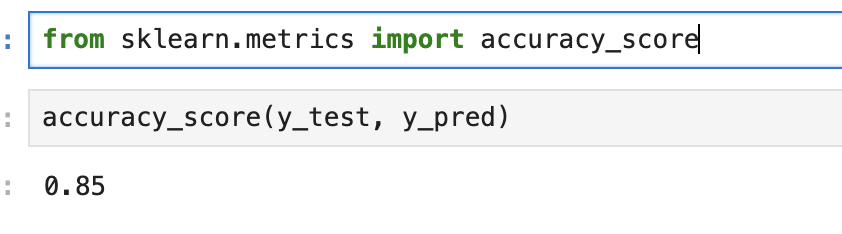
출력
0.85
TIP💡
한번에 다확인가능한 라이브러리 : classification_report
from sklearn.metrics import classification_report
classification_report(y_test, y_pred)
print( classification_report(y_test, y_pred) )
출력

4-2. 시각화
import seaborn as sb
sb.heatmap(data=cm, cmap='RdBu', annot=True, linewidths = 0.8)
plt.show()

4-3. 실제 데이터 예측
나이가 37세 이고 연봉이 37500일때, 이사람은 상품을 구매 할것인가?

np.array([ 37,37500])
new_data = np.array([ 37,37500])
new_data = new_data.reshape(1, 2)
new_data.shape
#(1, 2)
new_data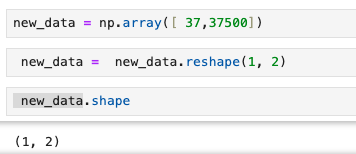
출력
array([0])
TIP💡
파일 저장
import joblib
# 파일 저장
joblib.dump(scaler_X,'scaler_X.pk1')
joblib.dump(classifier,'classifier.pk1')출력
['scaler_X.pk1']['classifier.pk1']728x90
반응형